
目录
- 系统发育树是不同生物之间关系的视觉表示,显示通过从共同的祖先到不同的后代的进化时间的路径。
- 序列比对显示的相关生物序列之间的相似性和分歧通常必须在系统发育树上的背景下具有合理化和可视化。因此,分子系统源是生物信息学的基本方面。
- 分子系统源是系统发育的分支,其分析遗传,遗传分子差异,主要在DNA序列中,以获得有关生物的进化关系的信息。
- 生物体中生物功能的相似性和生物体中的分子机制强烈暗示了种类从共同的祖先下降。分子系统源使用分子的结构和功能以及它们如何随时间改变以推断这些进化关系。
- 从这些分析中,可以确定物种之间的多样性的过程。分子发育分析的结果在系统发育树中表达。
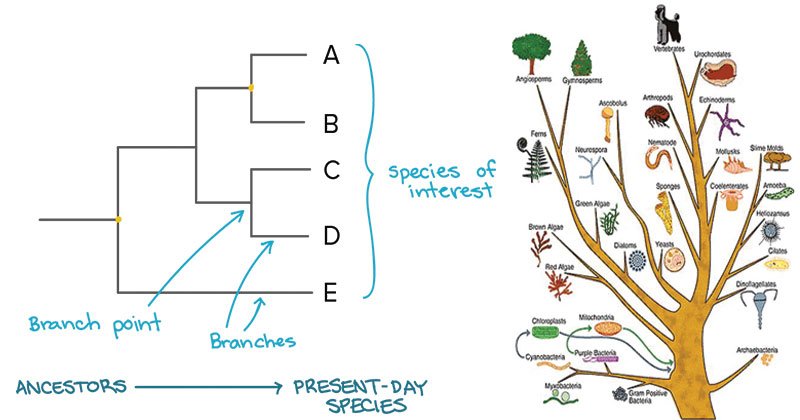
系统发育分析和生物信息学的作用
以DNA或蛋白质序列形式存在的分子数据也可以为现有生物体提供非常有用的进化视角,因为随着生物体的进化,遗传物质随着时间积累突变,导致表型变化。因为基因是记录累积突变的媒介,它们可以作为分子化石。通过对多个相关生物分子化石的比较分析,可以揭示基因乃至生物的进化史。
然而,系统发育推论众所周知难以努力,因为解决方案的数量爆炸地增加了分类群,并且可以通过使用较大的分类种类来调查进化生物学中的巨大数量的新问题。
但是,随着计算和使用阵列的生物信息学工具,可以在实际计算时间中分析大数据集,并产生具有高概率的最佳或接近最佳解决方案。响应于这种趋势,大部分目前的文学信息学(即计算系统发育学)的研究集中在更有效的启发式方法的发展。
系统发育分析步骤

系统发育分析的基本步骤包括:
- 组装并对齐数据集
- 第一步是鉴定感兴趣的蛋白质或DNA序列,并组装由其他相关序列组成的数据集。
- 可以使用NCBI BLAST或类似搜索工具检索感兴趣的DNA序列。
- 一旦选择和检索序列,就会创建多个序列对齐。
- 这涉及到在矩阵中排列一组序列以确定同源区域。
- 有许多网站和软件程序,如ClustalW、MSA、MAFFT和T-Coffee,旨在对给定的一组分子数据执行多重序列。
- 构建(估计)系统发育树从序列使用计算方法和随机模型
- 为了构建系统发育树,应用统计方法来确定树拓扑,并计算最能描述数据集中对齐序列的系统发育关系的分支长度。
- 应用的最常见的计算方法包括距离 - 矩阵方法,以及离散数据方法,例如最大分析和最大可能性。
- 有几个软件包,如Paup、PAML、PHYLIP,应用这些最流行的方法。
- 统计测试和评估估计的树木。
- 树估计算法生成一个或多个最佳树木。
- 这组可能的树木受到一系列统计测试,以评估一棵树是否优于另一棵树 - 以及提出的系统发生是合理的。
- 用于评估树木的常用方法包括自举和千刀重采样方法,以及分析方法,如差异,距离和可能性。
生物信息学工具用于系统发育分析
- 有几种生物信息学工具和数据库可用于系统发育分析。
- 这些包括Panther,P-Pod,PFAM,Treefam和Phylofacts结构系统常百科全书。
- 每个数据库使用不同的算法,利用不同的序列信息来源,因此,例如,PANTHER估计的树可能与P-Pod或PFam生成的树有很大的不同。
- 与所有这类生物信息学工具一样,重要的是测试不同的方法,比较结果,然后确定哪个数据库最适合涉及不同类型数据集的研究(根据共识结果)。
参考文献
- 熊j .(2006)。重要的生物信息学。德州农工大学。剑桥大学出版社。
- Arthur M Lesk(2014)。生物信息学介绍。牛津大学出版社。牛津,英国。
- Brown, D, K Sjölander(2006)“基于系统基因组推断的功能分类”。计算机科学与技术,2017,36(6):759 - 763。
- http://www.math.umaine.edu/~khalil/courses/mat500/papers/mat500_paper_phyloomenetics.pdf.
- https://www.ncbi.nlm.nih.gov/books/NBK21122/的
- http://www.bioinfbook.org/php/?q = chapter7.
- http://previouslife.lanevol.org/lane/molecular_phyloomenetics.html.
- https://www.slideshare.net/ajaychandra17/molecular-phyloonsetics.